
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- TensorFlow
- 아이패드
- pytorch로 시작하는 딥러닝
- 하나은행 공채
- 아이패드 필기
- 필기 어플
- 아이패드 필기어플
- deep learning
- 주석 단축키
- windows10
- 하나은행 인턴 후기
- 아이패드 노트쉘프
- 아이패드 논문
- 하나은행 인턴
- 아이패드 논문 필기
- 아이패드 noteshelf
- 딥러닝
- 굿노트
- Python
- 하나은행
- 노트쉘프
- pytorch
- liquid text
- 프로그래머스
- 논문 필기
- 파이썬
- GPU
- 2022 하나은행 인턴 후기
- Noteshelf
- 리퀴드텍스트
- Today
- Total
Azure Zest
[ 논문리뷰 ] SRGAN - Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network 본문
[ 논문리뷰 ] SRGAN - Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
LABONG_R 2019. 8. 1. 15:32Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
Super Resolution에 최초로 Deep Learning을 도입한 SRCNN 이후로 많은 모델들이 등장했다. 그 중 SRGAN은 질감의 디테일의 복구를 기반으로 만들어지게 되었다. 최근의 SR 방법들은 MSE를 최소화하여 PSNR을 높게 만드는 데 집중을 해 High frequency detail들을 잡는 데에는 만족스럽지 않은 결과를 나타낸다. 따라서 이 연구에서는 pixel space에서의 유사성이 아닌 perceptual similarity 에 기반한 content loss와 adversarial loss로 구성된 perceptual loss function을 이용한다.
Introduction
일반적으로 재구성된 SR 이미지에서는 보통 High frequency detail들이 부족하기 때문에 High upscaling factors에서 문제가 드러난다. 이를 위해 보통, MSE를 최소화시켜 PSNR을 최대화시키는 방법을 사용하는데, 이것이 꼭 좋은 SR 결과를 나타내는 것은 아니다. MSE는 픽셀 이미지의 차이를 기반으로 두었기 때문에 High texture detail같은 것들에는 제한적이다. 아래에 있는 사진에서 왼쪽의 수치값이 PSNR이고 오른쪽의 수치값이 SSIM 값이다. PSNR은 최고 신호의 전력대비 손실을 나타내고, SSIM은 구조적 유사지도로서 두 값들은 보통 Resolution을 나타낼 때 많이 쓰이는 정량적인 값이다. 이 때, Bicubic 이미지와 SRGAN 이미지를 비교하였을 때 SRGAN의 PSNR 값이 더 작음에도 불구하고 훨씬 더 좋은 resolution을 보이는 것을 알 수 있다.

Design of convolutional neural networks
Deeper network architectures은 훈련하기가 어려울 수 있지만, 매우 높은 복잡도의 모델링 매핑을 허용하기 때문에 네트워크의 정확성을 크게 높일 수 있는 가능성이 있다고 한다. 이러한 Deeper network architecture들을 효율적으로 학습시키기 위해 Batch normalization이 사용되는데, 내부의 Co-variate shift를 막기 위해 사용된다. 또한, Skip connections는 Network architectur을 완화시키고, Up scaling filter은 정확도와 스피드에 있어서 향상되게 하였다.

Loss functions
MSE같은 Pixel-wise loss function들은 High frequency detail들에 내재되어 있는 불확실성을 조절하기 위해 노력한다. 하지만 MSE를 예시로 들자면, MSE를 최소화하면 지나치게 smoothing하기 때문에 안좋은 Perceptual quality를 갖게 된다.
다른 방법으로, 한 매니폴드에서 다른 매니폴드로의 매핑을 train 하기위해 GAN이 사용되기도 한다. 특히, vgg19 네트워크에서 추출한 피쳐 맵 사이의 유클리드 거리를 바탕으로 한 손실 함수를 공식화하였다. 이는 Super resolution 및 스타일 전달(artistic style-transfer)에 대해 지각적으로 더 설득력 있는 결과를 낳았다.


Method
Single image super-resolution의 목표는 Low-resolution input image 에서 High-resolution image를 추정하는 것이다. 이 논문의 최종 목표는 주어진 LR input image를 그에 대응하는 HR image를 생성하는 generating function G를 train하는 것이다. 또한, Train하는 과정에서 Loss components의 조합으로 Perceptual loss를 설계할 것이다.
이 공식의 General idea는 Super resolution 이미지와 실제 영상을 구별하도록 Train된 구별자 D모델을 속이는 것을 목표로 Generator 모델인 G를 train 시키는 것이다. 사용한 방법은 Natural image의 하위 공간이 매니폴드에 존재하는 지각적으로 우수한 Solution을 장려하기 때문에 MSE 같이 Pixel-wise error을 측정하여 최소화시키는 방법들과 대조된다.
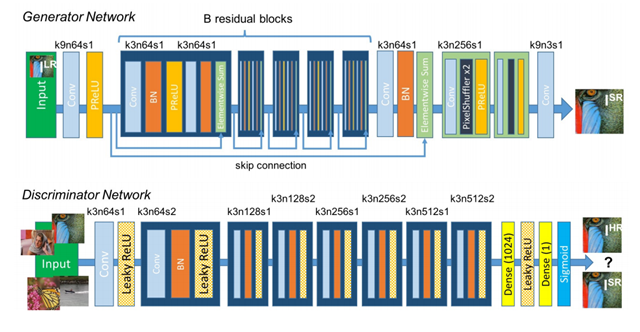
우선 Generator 모델을 만들 때, 핵심으로 동일한 레이아웃을 가진 B residual block이 있다. 모델은 3*3 커널과 64개의 피쳐 맵을 가진 두개의 컨볼루션 레이어를 사용하였고, batch normalization과 activation function으로 쓰인 parametricrelu(각 차원마다 학습된 relu를 사용하는)를 사용하였다. 또한, train되어 있는 2개의 sub-pixel convolution 레이어를 이용해 이미지의 해상도를 높였다.
Discriminator 모델의 경우, max-pooling을 방지하기 위해 leakyrelu activation을 사용하였고, 방정식의 최대화 문제를 해결하기 위해 train되었다.

픽셀단위의 MSE loss function은 아래식으로 계산된다. 이것은 SR에서 가장 널리 이용되는 Optimization 방법인데 실제 High resolution한 이미지 값과 Low resolution 이미지에서 만들어낸 Super resolution 이미지 값의 차이를 제곱하여 평균화한 값이 이 MSE loss으로 생각하였다. PSNR은 다음 공식과 같이 MSE 값이 분모에 있기 때문에 MSE값과 역수관계에 있다. 따라서, MSE 값이 낮아질수록 PSNR값이 높아지지만, 이같은 경우에는 너무 smoothing되기 때문에 High frequency contente값이 부족하여 texture가 잘 표현되지 않는다.

따라서 이 논문에서는 19계층의 vgg 네트워크의 ReLU 활성화 계층을 기반으로 VGG의 손실을 정의한다. 이 방법은 pre trained된 vgg net을 이용해서 feature map에서의 유클리드 거리(reference image 와 reconstructed image의 유클리드 거리 값)를 계산하는 방법이다. 따라서 pixel의 값에 중심을 두기보다 perceptual similarity를 주목하였기 때문에 보다 detail한 부분을 잘 잡아낼 수 있을 것으로 보인다.
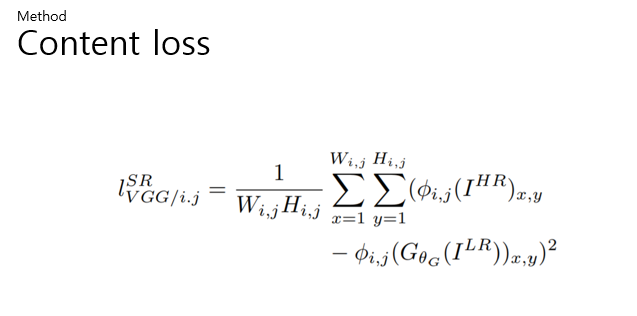
Generator가 Discriminator 모델을 속임으로써, Natural image와 비슷하게 만들 수 있도록 Content loss에 Adversarial loss를 더해준다. 이 Adversarial loss는 Discriminator가 Low resolution에서 생성된 이미지를 Natural high resolution image라고 구별할 확률을 기반으로 정의한다. 또한, 더 나은 동작을 위해서 Log를 1에서 뺀 것을 최소화시키는 것이 아닌 위의 식을 최소화시킨다.

앞서 말한 두 가지의 Loss functon을 더하여 최종적으로 아래와 같은 Perceptual loss function이 완성된다.

Experiments
Experiment를 위해 널리 사용되는 벤치마크 데이터 세트인 SET 5, SET 14, BSD100에 대해 실험을 수행하였고, 모든 실험은 저해상도와 고해상도 영상 사이에 4배의 척도 인수로 수행했다. 이는 곧 이미지 픽셀의 16배 감소에 해당한다. 데이터는 이미지넷에서 350000개의 이미지를 무작위로 샘플링하여 train 시켰다. SRResnet은 1000000회의 에포치로 , GAN은 원치않는 Local optimal를 피하기 위해 Generator 모델로 MSE 기반의 Srresnet을 사용하였고, 100000회의 에포치로 train 시켰다.
또한, 영상을 재구성하는 다양한 접근 방식에 대한 퍼포먼스를 정량화하기 위해서 mos 테스트를 수행하였다. 26명의 사람들에게 제일 나쁠 때 1로 제일 좋다의 5까지 총 5점 중 하나를 각 이미지의 12개 버전을 평가했다. 또한, 영상을 더 추가하여 Test-retest를 통해 신뢰성을 평가하였는데, 동일한 이미지의 등급사이에 큰 차이가 없어 좋은 신뢰도를 보였다. 아래의 결과에서 사람들이 평가한 SRGAN의 결과가 다른 모델의 결과에 비해 상당히 좋은 것을 알 수 있다.

이 표는 MOS를 포함한 다양한 Loss functions에 대한 ResNet과 GAN의 퍼포먼스 결과이다. 먼저 대체적으로 MSE를 사용한 모델이 앞서 말했듯, 역관계이기 때문에 PSNR이 높은 것을 확인할 수 있다. 또한, MSE Loss function을 이용하였을 때는 Adversarial loss와 결합할 때 제일 높은 PSNR 값은 갖지만, 사람들의 rating 값인 MOS 값은 떨어지는 것을 확인할 수 있었다. 이는 MSE 기반의 Content loss와 Adversarial loss의 경쟁에 의해 발생하는 것으로 추측하고 있다. 마지막으로 Set 5에서는 뚜렷히 나타나지 않지만, Set 14에서 vgg54의 Content loss값에 Adversarial loss 값을 더한 Srgan-vgg54 모델이 MOS 값이 가장 두드러지게 나타난 것을 확인할 수 있다. 또한, 앞서 있던 그림에 있던 srgan 모델이 이 srgan- vgg54 모델인데 두 그림과 표로 살펴보면, Srgan에서 texture의 질감표현, 혹은 High frequency의 디테일이 잘 표현되었다고 볼 수 있을 것 같다.

마지막으로 벤치마크 데이터에 대한 여러 방법들의 비교를 나타낸 표이다. 그림에서 보면 SRResnet에서 PSNR과 SSIM의 값이 두드러지는 것을 확인할 수 있고, SRGAN에서 MOS 값이 눈에 띄게 높은 것을 확인할 수 있다. 이는 SRGAN이 사실적 이미지에 대한 기술의 새로운 상태, 즉 기존의 PSNR이 Resolution에 있어서 큰 지표로 사용된것에 비해 PSNR이 엄청 높지않아도 사람들이 인식하는 High resolution이 다를수도 있다는 바를 의미한다고 생각한다.

위의 표에서 의미하는 바를 그림으로 살펴보면, 첫번째 사진이 MSE loss function을 이용한 SRResnet으로 만든 Super resolution image 이고, 네 번째 사진이 그 SRResnet을 generator로, vgg54의 content loss와 adversarial loss를 합한 값으로 Loss functio을 이용한 SRGAN으로 만든 Super resolution image 이다. 두 사진 모두 뛰어난 성능을 보이고 있지만, SRGAN에서 원숭이 피부나 홍채를 보면 좀 더 사실에 가까운 detail한 texture 질감을 보이는 것으로 보인다.

Discussion and future work

Reference
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
Despite the breakthroughs in accuracy and speed of single image super-resolution using faster and deeper convolutional neural networks, one central problem remains largely unsolved: how do we recover the finer texture details when we super-resolve at large
arxiv.org
Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network
Recently, several models based on deep neural networks have achieved great success in terms of both reconstruction accuracy and computational performance for single image super-resolution. In these methods, the low resolution (LR) input image is upscaled t
arxiv.org
'DIP & 라즈베리파이 & 아두이노 & 웹개발 & 논문리뷰' 카테고리의 다른 글
| [ 크롬 ] 크롬 개발자 도구 간단하게 사용해보기 (0) | 2020.05.05 |
|---|---|
| 웹개론 (0) | 2019.08.09 |
| [ Arduino ] Arduino Software 다운받기 (0) | 2019.07.18 |
| [ 논문리뷰 ] SRCNN - Image Super-Resolution Using Deep Convolutional Networks (1) | 2019.04.04 |
| [ 라즈베리파이 ] 라즈베리파이로 무선 ap 만들기 (11) | 2019.04.04 |



