
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 아이패드 논문
- Python
- 리퀴드텍스트
- windows10
- liquid text
- 딥러닝
- 아이패드 noteshelf
- 하나은행 공채
- 2022 하나은행 인턴 후기
- 아이패드 노트쉘프
- 노트쉘프
- 주석 단축키
- 아이패드
- 하나은행 인턴 후기
- 굿노트
- pytorch
- 아이패드 논문 필기
- pytorch로 시작하는 딥러닝
- 프로그래머스
- 하나은행
- 하나은행 인턴
- 논문 필기
- 아이패드 필기어플
- deep learning
- 필기 어플
- GPU
- Noteshelf
- 아이패드 필기
- 파이썬
- TensorFlow
- Today
- Total
Azure Zest
[ 논문리뷰 ] SRCNN - Image Super-Resolution Using Deep Convolutional Networks 본문
[ 논문리뷰 ] SRCNN - Image Super-Resolution Using Deep Convolutional Networks
LABONG_R 2019. 4. 4. 20:23이 논문은 2015년에 발표된 논문으로 SISR(single image super-resolution) 에 최초로 딥러닝을 적용한 논문으로써 의의가 있다. 이 후, 많은 논문에서 기반으로 사용하였고, 또한 간단한 구조로 기존의 SR 방법들을 능가하였기 때문에 많은 사람들이 SR 문제에 (깊은 구조의)딥러닝을 적용하는 계기가 되었다.
Training

우선, 전체적인 구조를 살펴보자면 위의 그림과 같다.
SRCNN은 저해상도 이미지를 input으로 받아 일련의 과정을 거친 뒤, 고해상도 이미지를 output으로 출력하게 된다.
그 일련의 과정을 수식으로 나타내면 다음과 같다.


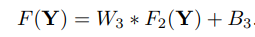
우선, 첫째로 'Patch extraction and representation'은 저해상도 이미지에서 patch들을 추출하는 과정이다. 이 patch들은 특징을 가지고, 두 번째로 'Non-linear mapping'에서 여기서 얻은 다차원의 patch들을 non-linear하게 다른 다차원의 patch들로 매핑을 하는 과정이다. 마지막으로 'Reconstruction'에서는 이 다차원 patch들로부터 고해상도 이미지를 복원시키는 것이다. 이 과정들은 3개의 convolutional layer로 이루어져 실행된다.
또한, 학습시킬 때의 loss function은 MSE를 사용하였다.

MSE loss function은 보통의 딥러닝 모델들에 많이 쓰이는 function으로 평균제곱오차값이다. 물론 전체적인 학습에 효과는 좋지만 이 후 high frequency의 특징들을 잘 못 잡아내기 때문에 다른 loss function을 사용한 SR 딥러닝 모델들이 등장하게 된다.
Experiments
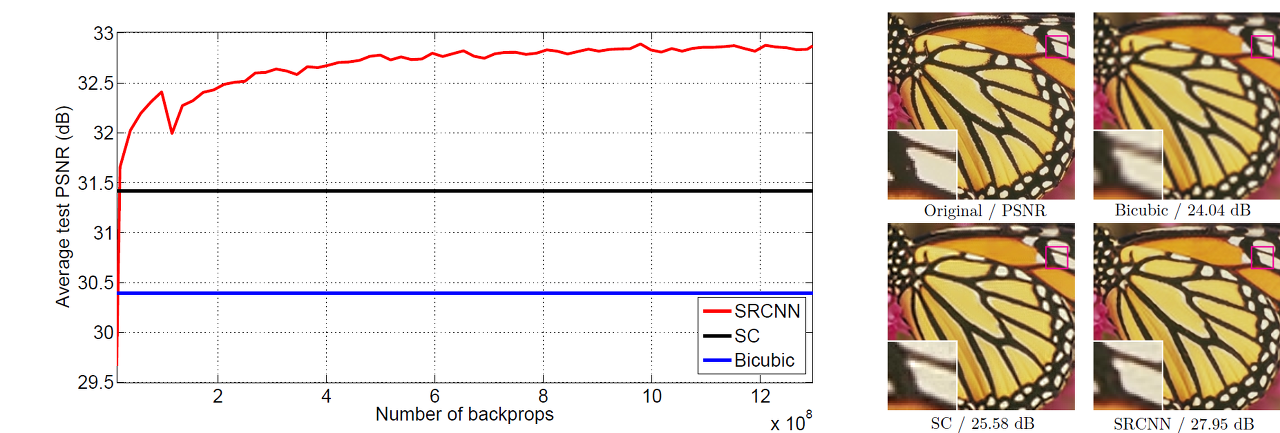
위의 그래프는 Original, Bicubic, Sparse-coding-based method(SC), SRCNN에 대한 PSNR 값의 비교 그래프와 사진이다. 우선 PSNR 값은 신호가 가질 수 있는 최대 전력에 대한 잡음의 전력이라고 정의되어 있다. 다음과 같이 수식으로도 나타낼 수 있는데 정의에서와 같이 최대 전력에 대한 잡음의 비이기 때문에 높을수록 해상도가 높은 것으로 여겨지며, 해상도의 척도로써 많이 쓰인다. 따라서 위의 그래프를 살펴 보았을 때, SC나 Bicubic의 PSNR 값보다 SRCNN의 PSNR 값이 훨씬 높은 것으로 보아 해상도가 더 좋다는 것을 알 수 있다. 또한, 옆의 사진에서의 비교를 봐도 두 방법보다는 나비의 날개부분의 문양이 좀 더 덜 blur하다는 것이 보인다.
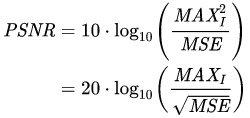

위의 사진은 training할 때의 data의 수에 따른 SRCNN의 PSNR의 값을 비교한 그래프이다. 점선이 ImageNet을 이용하여 training한 그래프이고, 실선이 91개의 이미지로 training한 그래프이다. PSNR값은 확실히 훨씬 더 많은 양의 이미지 데이터를 이용했을 때 높게 나왔다.

다음은 filter의 크기를 달리 했을 때의 PSNR 값을 비교한 그래프이다. 빨간색의 실선 그래프가 filter의 크기를 키웠을 때의 결과인데 filter의 크기를 키울수록 더 높은 PSNR 값을 보였다. 이는 filter의 크기가 클수록 특징을 더 잘 받아들이기 때문인 것으로 추측하고 있다.

A의 그래프에서 구조를 더 깊게 했을 때 오히려 결과가 더 안좋아지는 모습을 볼 수 있었다. 위의 그래프는 filter size를 고정하고, non-linear mapping layer를 달리했을 때의 그래프인데 초록색 그래프가 9-1-1-1-5로 더 깊게 layer을 늘렸을 때의 결과이다. 오히려 기존의 3개의 layer 결과보다 훨씬 성능이 떨어지는 것을 확인할 수 있었다.

이것은 기존의 SR 방법들과 더불어 SRCNN의 PSNR을 비교한 그래프이다. 위의 SRCNN만 딥러닝을 이용한 SR기법이고, 나머지는 기존의 방법들인데 SRCNN이 속도도 빠르면서 훨씬 더 PSNR 값이 높은 것을 확인할 수 있었다. 이로써 SR에 있어서 딥러닝을 적용시켰을 때 꽤 좋은 성능을 보이는 것을 보여주었고, 이 후 많은 더 깊은 구조의 모델을 이용해 SR에 적용시키는 계기가 되었다. 또한, 이 논문에서는 luminance 채널(YCbCr에서 Y)에만 적용시켰지만, 이후의 연구에서 RGB 채널에 적용시켰을 때 더욱 좋은 결과를 나타났다고 한다.
Reference : Image Super-Resolution Using Deep Convolutional Networks
'DIP & 라즈베리파이 & 아두이노 & 웹개발 & 논문리뷰' 카테고리의 다른 글
| [ 논문리뷰 ] SRGAN - Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network (2) | 2019.08.01 |
|---|---|
| [ Arduino ] Arduino Software 다운받기 (0) | 2019.07.18 |
| [ 라즈베리파이 ] 라즈베리파이로 무선 ap 만들기 (11) | 2019.04.04 |
| [ 라즈베리파이 ] 라즈베리 파이로 고정 ip 할당하기 (0) | 2019.04.04 |
| [ 라즈베리파이 ] 라즈베리파이 Raspbian 깔기!! (0) | 2019.01.24 |

